# PLT 表与 GOT 表 | 延迟绑定机制学习
# 前置知识
# 符号及符号表
在编程语言中,不可避免的要定义全局变量,函数.
在编译器编译源文件的时候,函数名转换为内存地址的引用,未定义的函数名要分配重定位条目,已初始化且初始化不为 0 变量要存入.data 节,初始化为 0 的存入.bss 节,未初始化的则指向 COMMON 伪节中.
执行这些操作,需要一个合适的数据结构以组织这些信息和高效的获取数据。于是这一个个的函数名和全局变量名就称为符号,并有序的组织在一起,称为符号表.
这里做个测试
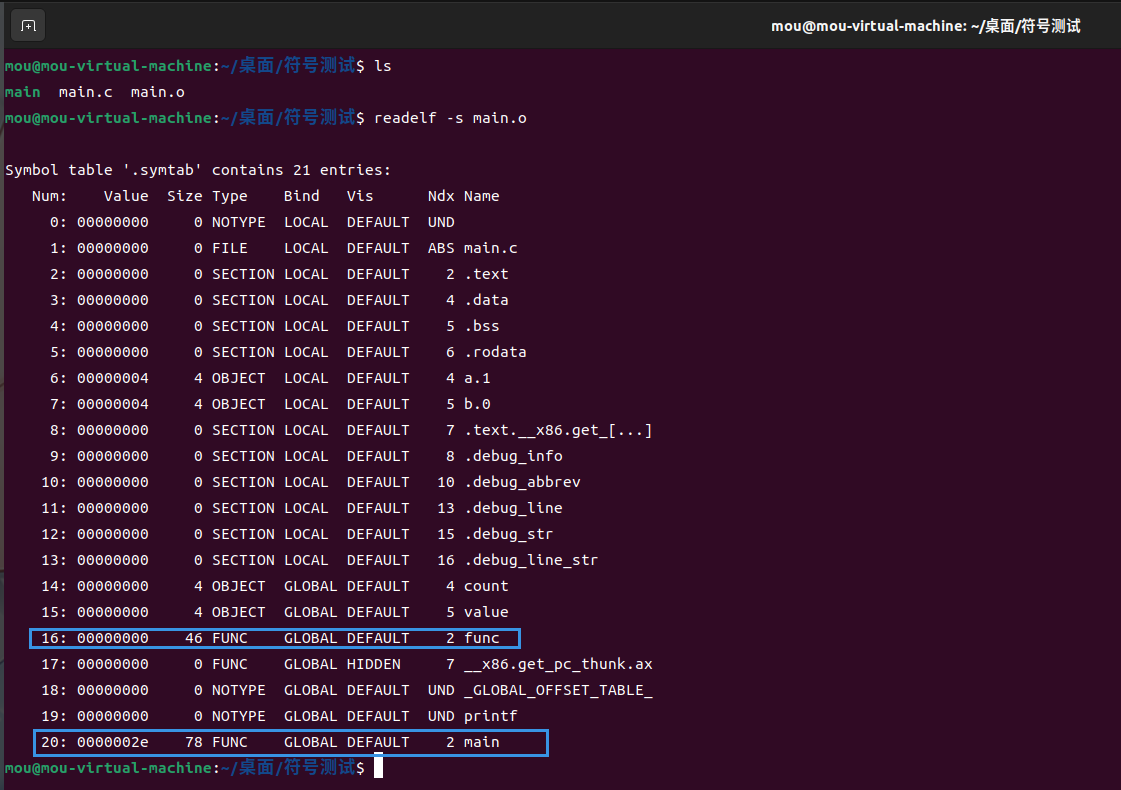
首先我们来看符号 main 和 func。在源程序中定义了两个函数,分别是函数 main 和函数 func,所以符号表中二者的类型是函数。又函数 main 和 func 是全局可见的,因此这里的 Bind 字段也是全局的 (GLOBAL)。关于 Ndx 表示的是 section 的索引值。关于索引值与具体 section 的对应关系,可以查看 section header table 来确定
又函数 main 和 func 所在的位置是 text section, 所以这里符号 main 和 func 的 Ndx 为 2
Value (16 进制) 表示函数相对于.text section 起始位置的偏移量 Size 表示所占字节数 由图知函数 func 是从 0 开始,大小是 46 个字节 所以函数 main 的起始地址是 0x2e (46), 紧跟在函数 func 之后 字段 Vis 在 C 语言中没有使用 我们可以忽略这个字段
关于符号 printf 虽然他也是个函数 但是函数 printf 只是在 main.c 中被引用,由于它的定义并不在 main.c 中,所以它的 Ndx 是 UND (undefine) 的类型
关于全局变量 count 和 value, 符号表中类型是 OBJECT 表明该符号是个数据对象 (变量和数组等在符号表中的类型都用 OBJECT 来表示) 虽然二者都是全局变量 但二者 Ndx 值不同也就是说二者处于不同的 section 中 导致二者位于不同 section 的原因是 count 经过了初始化,而 value 没有
main.c 中还定义了一个局部变量 x 这个局部变量没有出现在符号表中,这是因为局部变量在运行时是在栈中被管理,链接器对此类符号并不感兴趣,所以局部变量的信息不会出现在符号表中
# 动态链接与静态链接
关于动态链接与静态链接,大佬打了个比方:如果我的文章引用了别人的一部分文字,在我发布文章的时候把别人的段落复制到我的文章里面就属于静态连接,而做一个超链接让你们自己去看就属于动态链接了
# 静态链接
一段代码从文本编辑器上产生到最终能够在机器上运行,经历了非常多的阶段,概括而言,至少包含了以下几个阶段:
- 编译:编译器通过词法分析,语法分析,语义分析等,将一段代码翻译成汇编语言
- 汇编:将汇编语言翻译成机器指令
- 链接:解决符号之间的重定位问题
- 装载:将可执行文件加载到内存
静态链接就是在装载之前,就完成所有的符号引用的一种链接方式。静态链接的处理过程分为 2 个步骤:
- 空间与地址的分配。扫描所有的目标文件,合并相似段,收集当中所有的符号信息。
- 符号解析与重定位。调整代码位置。
静态链接的优缺点
- 优点: 简单
- 缺点:
- 浪费内存空间。在多进程的操作系统下,同一时间,内存中可能存在多个相同的公共库函数。
- 程序的开发与发布流程受模块制约。 只要有一个模块更新,那么就需要重新编译打包整个代码。
为了解决以上 2 个问题,就诞生了动态链接。
# 动态链接
基本思想就是将对符号的重定位推迟到程序运行时才进行。
只要推迟到运行时进行符号的重定位,就能解决静态链接的两个缺点。
对于第一个缺点:在运行时重定位,如果在运行过程中调用了公共库函数或者其他模块的函数,系统只需要在内存中维护一份公共库代码即可,只要将不同应用程序对公共库函数的调用地址设置成相同即可。
对于第二个缺点:理论上只要将需要替换的模块更新,无需将整个应用程序打包。
对于静态链接来说,系统只需要加载一个文件(可执行文件)到内存即可,但是在动态链接下,系统需要映射一个主程序和多个动态链接模块,因此,相比于静态链接,动态链接使得内存的空间分布更加复杂。
# PLT&GOT
linux 下的动态链接是通过 PLT&GOT 来实现的
这里来看一个现成的 c 语言编写的还未链接的.o 文件
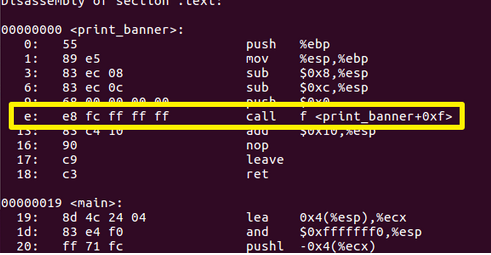
printf () 和函数是在 glibc 动态库里面的,只有当程序运行起来的时候才能确定地址,所以此时的 printf () 函数先用 fc ff ff ff 也就是有符号数的 -4 代替
运行时进行重定位是无法修改代码段的,只能将 printf 重定位到数据段,但是已经编译好的程序,调用 printf 的时候怎么才能找到这个地址呐?
链接器会额外生成一小段代码,通过这段代码来获取 printf () 的地址,像下面这样,进行链接的时候只需要对 printf_stub () 进行重定位操作就可以
.text | |
... | |
// 调用printf的call指令 | |
call printf_stub | |
... | |
printf_stub: | |
mov rax, [printf函数的储存地址] // 获取printf重定位之后的地址 | |
jmp rax // 跳过去执行printf函数 | |
.data | |
... | |
printf函数的储存地址,这里储存printf函数重定位后的地址 |
总体来说,动态链接每个函数需要两个东西:
1、用来存放外部函数地址的数据段
2、用来获取数据段记录的外部函数地址的代码
对应有两个表,一个用来存放外部的函数地址的数据表称为全局偏移表(GOT, Global Offset Table),那个存放额外代码的表称为程序链接表(PLT,Procedure Link Table)
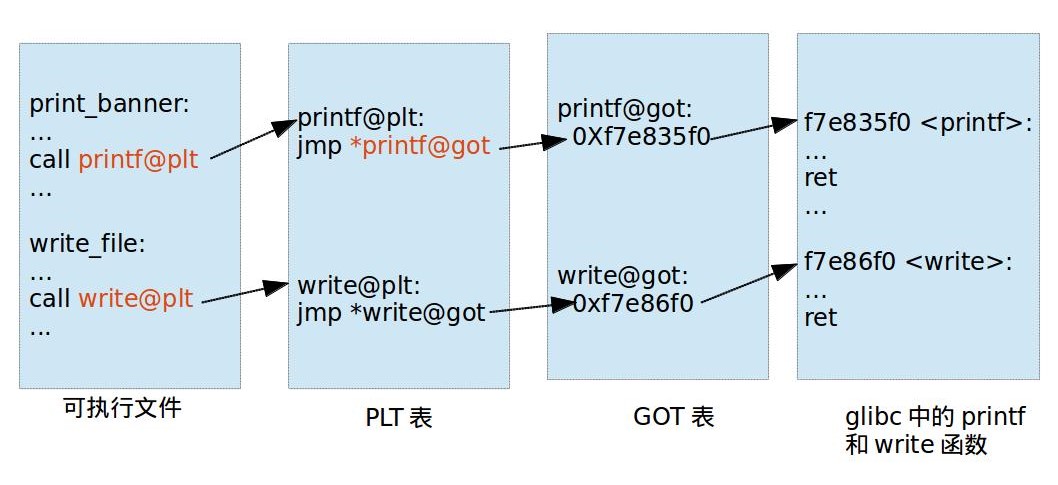
可执行文件里面保存的是 PLT 表的地址,对应 PLT 地址指向的是 GOT 的地址,GOT 表指向的就是 glibc 中的地址
那我们可以发现,在这里面想要通过 plt 表获取函数的地址,首先要保证 got 表已经获取了正确的地址,但是在一开始就进行所有函数的重定位是比较麻烦的,为此,linux 引入了延迟绑定机制
# 延迟绑定
只有动态库函数在被调用时,才会地址解析和重定位工作,为此可以使用类似这样的代码来实现:
// 一开始没有重定位的时候将 printf@got 填成 lookup_printf 的地址 | |
void printf@plt() | |
{ | |
address_good: | |
jmp *printf@got | |
lookup_printf: | |
调用重定位函数查找 printf 地址,并写到 printf@got | |
goto address_good;// 再返回去执行 address_good | |
} |
说明一下这段代码工作流程,一开始,printf@got 是 lookup_printf 函数的地址,这个函数用来寻找 printf () 的地址,然后写入 printf@got,lookup_printf 执行完成后会返回到 address_good,这样再 jmp 的话就可以直接跳到 printf 来执行了
也就是说这样的机制的话如果不知道 printf 的地址,就去找一下,知道的话就直接去 jmp 执行 printf 了
关于这个怎么找的笔记因为测试时候忘记截图了就没贴上来了 下面说些结论
在想要调用的函数没有被调用过,想要调用他的时候,是按照这个过程来调用的
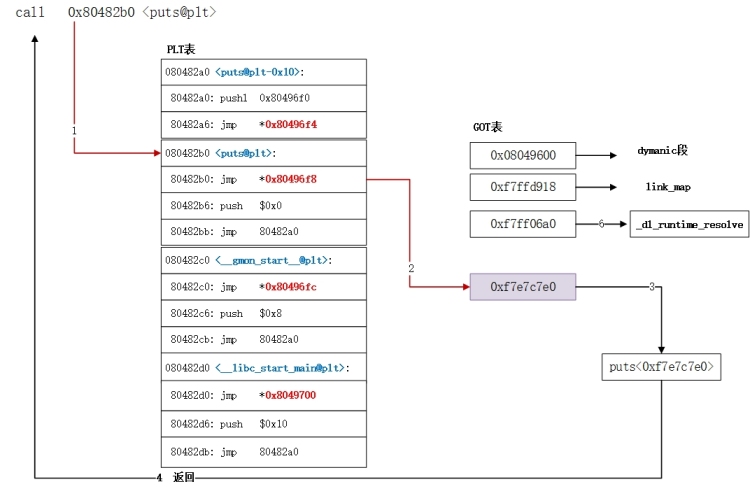
xxx@plt -> xxx@got -> xxx@plt -> 公共 @plt -> _dl_runtime_resolve
在 i386 架构下,除了每个函数占用一个 GOT 表项外,GOT 表项还保留了3个公共表项,也即 got 的前3项,分别保存:
got [0]: 本 ELF 动态段 (.dynamic 段)的装载地址
got [1]:本 ELF 的 link_map 数据结构描述符地址
got [2]:_dl_runtime_resolve 函数的地址
动态链接器在加载完 ELF 之后,都会将这3地址写到 GOT 表的前3项
流程图:
第一次调用:
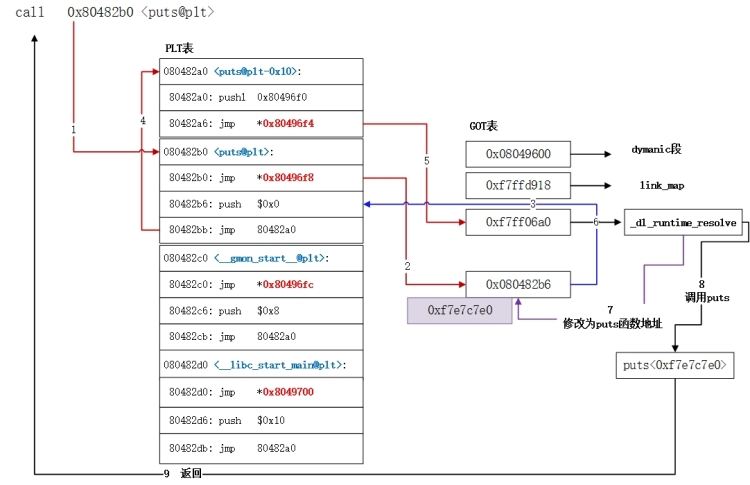
之后再次调用: