# 第一章 计算机系统漫游
# 1.1 信息就是位 + 上下文
1. 文件都以字节序列方式存储,只由 ASCII 字符构成称为文本文件,其他所有文件称为二进制文件
2. 区分相同位串代表的不同数据对象的唯一方法是我们读到这些数据对象时的上下文,不同上下文中,同样的字节序列可能表示一个整数浮点数字符串或者机器指令
# 1.2 程序被其他程序翻译成不同的格式
1. 把源程序文件 hello.c 翻译成可执行目标文件 hello 的过程有四个阶段(预处理,编译,汇编,链接) ,分别由预处理器,编译器,汇编器,链接器一同完成,他们共同构成了编译系统(看书上图片)
2. 预处理阶段:预处理器(cpp)根据 #开头的命令修改原始的 C 程序,并得新的 C 程序(以.i 为扩展名)
3. 编译阶段:编译器(cll)将 hello.i 翻译成文本文件 hello.s,包含一个汇编语言程序
4. 汇编阶段:汇编器(as)把 hello.s 翻译成机器语言指令,并把这些指令打包成可重定位目标程序的格式,结果保存在 hello.o(二进制文件)
5. 链接阶段:hello 调用了 printf 函数,printf 函数存在于一个名为 printf.o 的单独的预处理好的目标文件中。有链接器(ld)把 printf.o 合并到 hello.o 当中。结果得到 hello 文件
# 1.3 了解编译系统如何工作的好处
- 优化程序性能
- 理解链接时出现的错误
- 避免安全漏洞
# 1.4 处理器读并解释存在内存中的指令
# shell
hello.c 源程序已经被编译系统翻译成可执行文件 hello 并被存放在磁盘上。要想在 Unix 系统上运行该可执行文件,我们将它的文件名输入到称为 shell 的应用程序
linux> ./hello
hello, world
linux>
shell 是一个命令行解释器如果命令行的第一个单词不是 shell 的内置命令,那么 shell 就会假设他是个可执行文件的名字,他将加载并执行这个文件。
# 硬件
1. 系统硬件组成:总线,I/O 设备,主存,处理器
2. 总线:贯穿整个系统的一组电子管道,携带信息字节并负责在各个部件间传递(传递信息用的)通常总线被设计成传送定长的字节块(字 word)。字中的字节数是一个基本的系统参数(32 位 4 个,64 位 8 个)
3.I/O 设备:系统与外部世界联系通道(鼠标键盘,显示器,磁盘),I/O 通过控制器(I/O 设备本身或者主印刷电路板上的芯片组)或适配器(插在主板插槽)与总线相连
4. 主存:临时存储设备,处理器执行程序的时候用来存放程序和数据的,有一组动态随即存取存储器(DRAM)芯片组成
5. 处理器:中央处理器(CPU)是解释(或执行)存储在主存中指令的引擎。其和行是一个代写哦啊为一个字的存储设备(或寄存器),称为程序计数器(PC),在任何时候 PC 都指向主存中的某条机器指令(及含有该指令的地址)。处理器从 PC 指向的内存处读指令,解释指令中的位,然后更新 PC,使其指向下一条指令,而这些指令不一定在内存中连续
。处理器操作主要围绕主存,寄存器文件,算数 / 逻辑单元进行
6. 寄存器文件(register file)是一个小存储设备,由一些单个字长的寄存器组成,每个寄存器有唯一的文件。
7.** 算术 / 逻辑单元(ALU)** 计算数据和地址值
CPU 在指令的要求下可能执行的操作如下
| 操作 | 具体 |
|---|---|
| 加载 | 从主存复制一个字节或字到寄存器,以覆盖寄存器原来的内容 |
| 存储 | 从寄存器复制一个字节或字到主存的某个位置,覆盖主存原来的内容 |
| 操作 | 把两个寄存器的内容复制到 ALU,ALU 对这两个字做算术运算,并将结果存放到一个寄存器中,以覆盖寄存器原来内容 |
| 跳转 | 从指令本身抽取一个字,并将这个字复制到 PC 以覆盖 PC 原来的值 |
# 进程
进程可以看成是操作系统对正在运行的程序的一种抽象,在一个系统中可以运行多个进程,这些进程对外表现好像是独占硬件,实际上是通过不同进程之间进程的交互执行实现的,这个过程叫上下文切换(context switch)
# 线程
一个进程可以由多个线程组成,运行在一个上下文环境中,共享代码以及全局数据。因为共享数据,使得其比一般的进程更加高效(花在 context switch 的时间少)。
# 虚拟存储器
给进程提供的一个好像自己独占主存的假象,对于进程的所使用的虚拟存储器可以分成一下几个部分:
- 程序代码和数据
- 堆,可以动态扩展或者收缩,供像 malloc 和 free 这样的 C 语言中的库进行调用
- 共享库
- 栈,可以动态扩展或者收缩,用于编译器的函数调用
- 内核虚拟存储器
# 第三章 程序的机器级表示
https://ouuan.moe/post/2022/09/csapp-3 这个笔记博客好
操作数有 3 种基本类型:
- 立即数 —— 用数字文本表达式
- 寄存器操作数 —— 使用 CPU 内已命名的寄存器
- 内存操作数 —— 引用内存位置
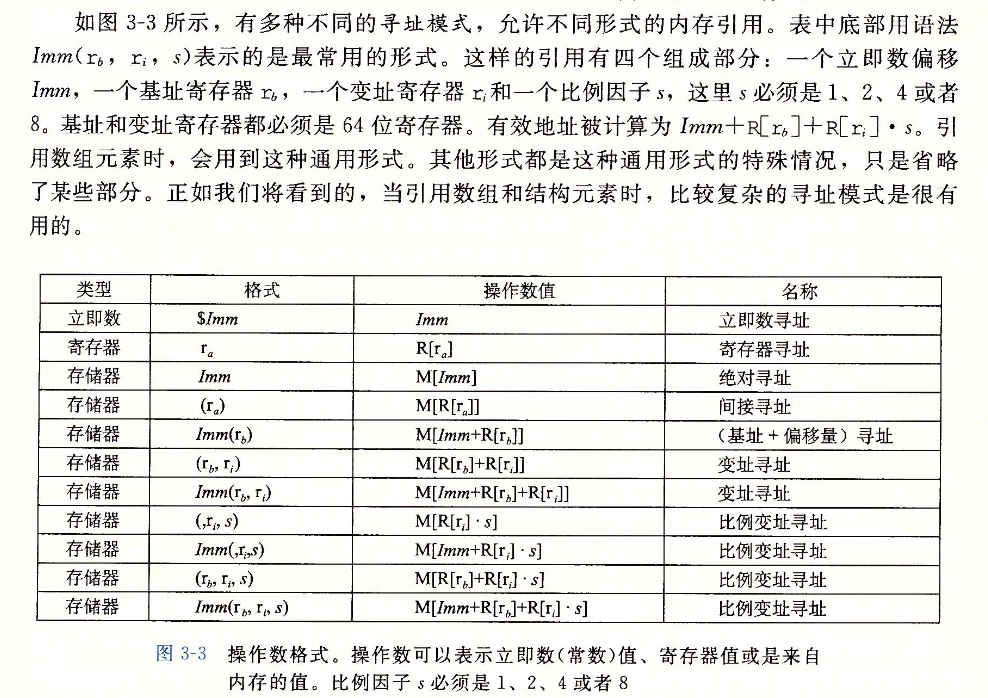
各种不同的操作数的可能性被分为三种类型。第一种类型是立即数 (immediate),用来表示常数值。在 ATT 格式的汇编代码中,立即数的书写方式是‘-577 或 $0x1F。不同的指令允许的立即数值范围不同,汇编器会自动选择最紧凑的方式进行数值编码。第二种类型是寄存器 (register),它表示某个寄存器的内容,16 个寄存器的低位 1 字节、2 字节、4 字节或 8 字节中的一个作为操作数,这些字节数分别对应于 8 位、16 位、32 位或 64 位。在图 3-3 中,我们用符号 r。来表示任意寄存器 a,用引用 R [r。] 来表示它的值,这是将寄存器集合看成一个数组 R,用寄存器标识符作为索引。第三类操作数是内存引用,它会根据计算出来的地址 (通常称为有效地址) 访问某个内存位置。因为将内存看成一个很大的字节数组,我们用符号 M,[Addr] 表示对存储在内存中从地址 Addr 开始的 b 个字节值的引用。为了简便,我们通常省去下标 b。
# 指令集的 reference:ATT 格式 vs Intel 格式
CS:APP 以及 gcc,OBJDUMP 默认使用的是 ATT 格式的汇编,其他一些编程工具,包括 Microsoft 的工具,以及来自 Intel 的文档,其汇编代码都是 Intel 格式的。这两种格式在许多方面有所不同。使用下述命令行,GCC 可以产生 multstore 函数的 Intel 格式的代码:
linux> gcc -Og -s -masm=intel mstore.c
我们看到 Intel 和 ATT 格式在如下方面有所不同:
Intel 代码省略了指示大小的后缀。我们看到指令 push 和 mov,而不是 pushq 和 movq。Intel 代码省略了寄存器名字前面的‘%' 符号,用的是 rbx,而不是 % rbx。
Intel 代码用不同的方式来描述内存中的位置,例如是‘QWORD PTR [rbx]' 而不是‘(% rbx)’。
在带有多个操作数的指令情况下,列出操作数的顺序相反。当在两种格式之间进行转换的时候,这一点非常令人困惑。虽然在我们的表述中不使用 Intel 格式,但是在来自 Intel 和 Microsoft 的文档中,你会遇到它。
x86-64 寄存器

补码 / 反码、零扩展和符号位扩展:
https://blog.csdn.net/weixin_40539125/article/details/103058420
# 第七章 链接
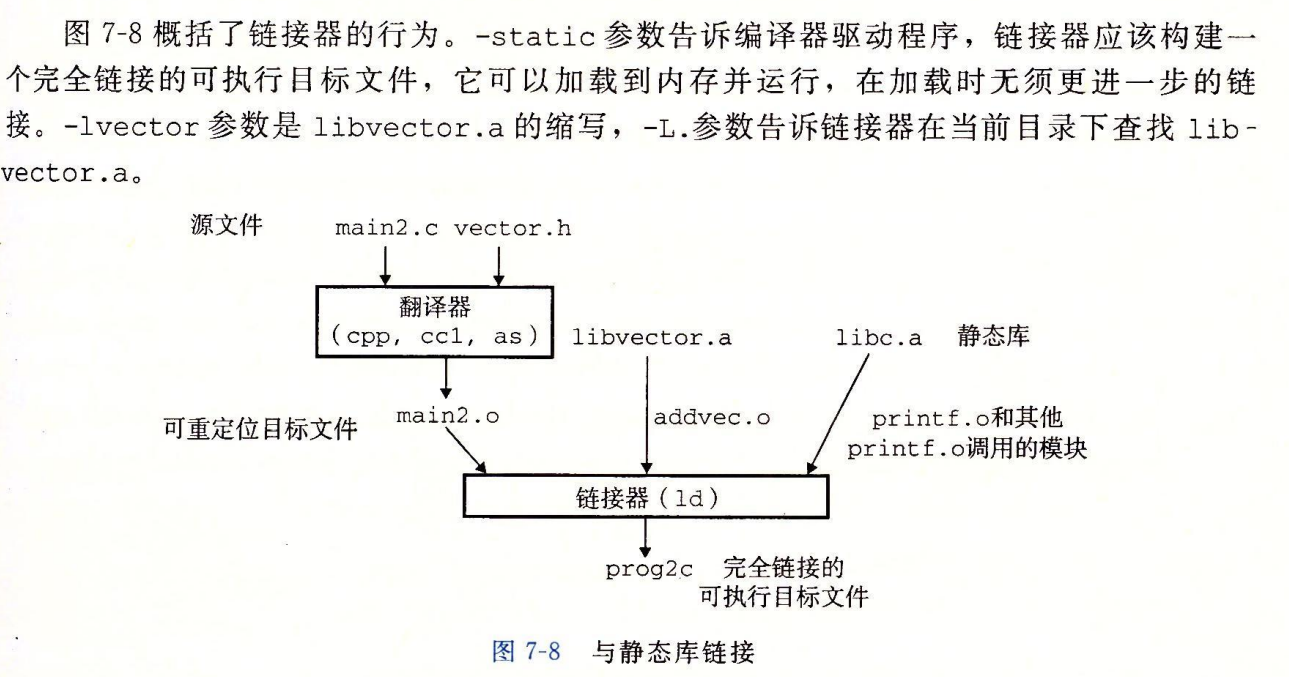
链接( Clinking)是将各种代码和数据片段收集并组合成为一个单一文件的过程,这个文件可被加载(复制)到内存并执行。链接可以执行于编译时( compile time),也就是在源代码被翻译成机器代码时;也可以执行于加载时( load time),也就是在程序被加载器(lad er)加载到内存并执行时;甚至执行于运行时( run time),也就是由应用程序来执行。在早期的计算机系统中,链接是手动执行的。在现代系统中,链接是由叫做链接器( linker)的程序自动执行的。
静态链接
像 Linux LD 程序这样的静态链接器以一组可重定位目标文件和命令行参数作为输入,生成一个完全链接的、可以加载和运行的可执行目标文件作为输出。输入的可重定位目标文件由各种不同的代码和数据节( section)组成,每一节都是一个连续的字节序列。指令在一节中,初始化了的全局变量在另一节中,而未初始化的变量又在另外节中。
为了构造可执行文件,链接器必须完成两个主要任务:
符号解析( symbol resolution)。目标文件定义和引用符号,每个符号对应于一个函数、一个全局变量或一个静态变量(即 C 语言中任何以 static 属性声明的变量)。符号解析的目的是将每个符号引用正好和一个符号定义关联起来。
重定位( relocation)。编译器和汇编器生成从地址 0 开始的代码和数据节。链接器通过把每个符号定义与一个内存位置关联起来,从而重定位这些节,然后修改所有对这些符号的引用,使得它们指向这个内存位置。链接器使用汇编器产生的重定位条目( relocation entry)的详细指令,不加甄别地执行这样的重定位。
# 目标文件
目标文件有三种形式:
可重定位目标文件。包含二进制代码和数据,其形式可以在编译时与其他可重定位目标文件合并起来,创建一个可执行目标文件可执行目标文件。包含二进制代码和数据,其形式可以被直接复制到内存并执行。(main.o)
可执行目标文件。包含二进制代码和数据,其形式可以被直接复制到内存并执行。(prog)
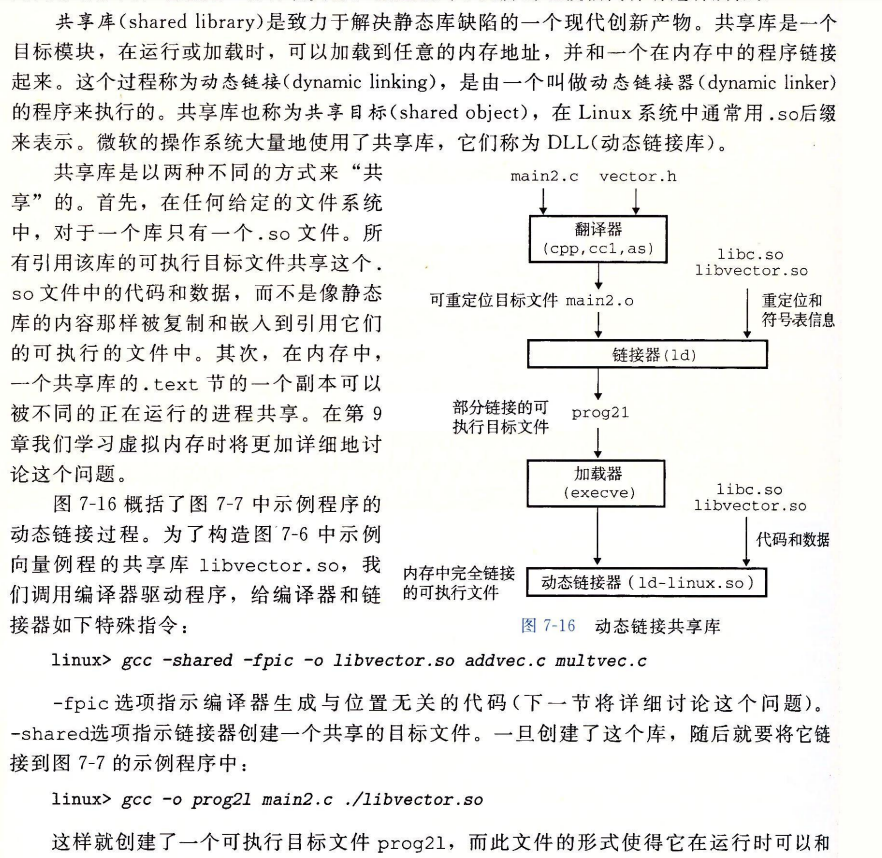
共享目标文件。一种特殊类型的可重定位目标文件,可以在加载或者运行时被动态地加载进内存并链接。
编译器和汇编器生成可重定位目标文件(包括共享目标文件)。链接器生成可执行目标文件。

.text:已编译程序的机器代码。
.rodata:只读数据,比如 printf 语句中的格式串和开关语句的跳转表。
.data:已初始化的全局和静态 C 变量。局部 C 变量在运行时被保存在栈中,既不出现在,data 节中,也不出现在.bss 节中
.bss:未初始化的全局和静态 C 变量,以及所有被初始化为 0 的全局或静态变量。在目标文件中这个节不占据实际的空间,它仅仅是一个占位符。目标文件格式区分已初始化和未初始化变量是为了空间效率:在目标文件中,未初始化变量不需要占据任何实际的磁盘空间。运行时,在内存中分配这些变量,初始值为 0。
.symtab:一个符号表,它存放在程序中定义和引用的函数和全局变量的信息。一些程序员错误地认为必须通过 - g 选项来编译一个程序,才能得到符号表信息。实际上,每个可重定位目标文件在. symtab 中都有一张符号表(除非程序员特意用 STRIP 命令去掉它)。然而,和编译器中的符号表不同, symtab 符号表不包含局部变量的条目。
.rel.text:一个.text 节中位置的列表,当链接器把这个目标文件和其他文件组合时,需要修改这些位置。一般而言,任何调用外部函数或者引用全局变量的指令都需要修改。另一方面,调用本地函数的指令则不需要修改。注意,可执行目标文件中并不需要重定位信息,因此通常省略,除非用户显式地指示链接器包含这些信息。
.rel.data:被模块引用或定义的所有全局变量的重定位信息。一般而言,任何已初始化的全局变量,如果它的初始值是一个全局变量地址或者外部定义函数的地址,都需要被修改。
.debug:一个调试符号表,其条目是程序中定义的局部变量和类型定义,程序中定义和引用的全局变量,以及原始的 C 源文件。只有以 - g 选项调用编译器驱动程序时,才会得到这张表。
.line:原始 C 源程序中的行号和.text 节中机器指令之间的映射。只有以 - g 选项调用编译器驱动程序时,才会得到这张表。
.strtab:一个字符串表,其内容包括. symtab 和, debug 节中的符号表,以及节头部中的节名字。字符串表就是以 null 结尾的字符串的序列。
# 符号和符号表
每个可重定位目标模块 m 都有一个符号表,它包含 m 定义和引用的符号的信息。在链接器的上下文中,有三种不同的符号:
由模块 m 定义并能被其他模块引用的全局符号。全局链接器符号对应于非静态的 C 函数和全局变量。
由其他模块定义并被模块 m 引用的全局符号。这些符号称为外部符号,对应于在其他模块中定义的非静态 C 函数和全局变量。
只被模块 m 定义和引用的局部符号。它们对应于带 static 属性的 C 函数和全局变量。这些符号在模块 m 中任何位置都可见,但是不能被其他模块引用。
如何解析多重定义的全局符号
链接器的输入是一组可重定位目标模块。每个模块定义一组符号,有些是局部的(只对定义该符号的模块可见),有些是全局的(对其他模块也可见)。如果多个模块定义同名的全局符号,会发生什么呢?下面是 Linux 编译系统采用的方法。
在编译时,编译器向汇编器输出每个全局符号,或者是强( strong)或者是弱(weak),而汇编器把这个信息隐含地编码在可重定位目标文件的符号表里。函数和已初始化的全局变量是强符号,未初始化的全局变量是弱符号。
根据强弱符号的定义, Linux 链接器使用下面的规则来处理多重定义的符号名
规则 1:不允许有多个同名的强符号。
规则 2:如果有一个强符号和多个弱符号同名,那么选择强符号。
规则 3:如果有多个弱符号同名,那么从这些弱符号中任意选择一个。
# 重定位
一旦链接器完成了符号解析这一步,就把代码中的每个符号引用和正好一个符号定义(即它的一个输入目标模块中的一个符号表条目)关联起来。此时,链接器就知道它的输入目标模块中的代码节和数据节的确切大小。现在就可以开始重定位步骤了,在这个步骤中,将合并输入模块,并为每个符号分配运行时地址。重定位由两步组成:
重定位节和符号定义。在这一步中,链接器将所有相同类型的节合并为同一类型的新的聚合节。例如,来自所有输入模块的.data 节被全部合并成一个节,这个节成为输出的可执行目标文件的.data 节。然后,链接器将运行时内存地址赋给新的聚合节,赋给输人模块定义的每个节,以及赋给输人模块定义的每个符号。当这一步完成时,程序中的每条指令和全局变量都有唯一的运行时内存地址了。
重定位节中的符号引用。在这一步中,链接器修改代码节和数据节中对每个符号的引用,使得它们指向正确的运行时地址。要执行这一步,链接器依赖于可重定位目标模块中称为重定位条目( relocation entry)的数据结构,我们接下来将会描述这种数据结构。
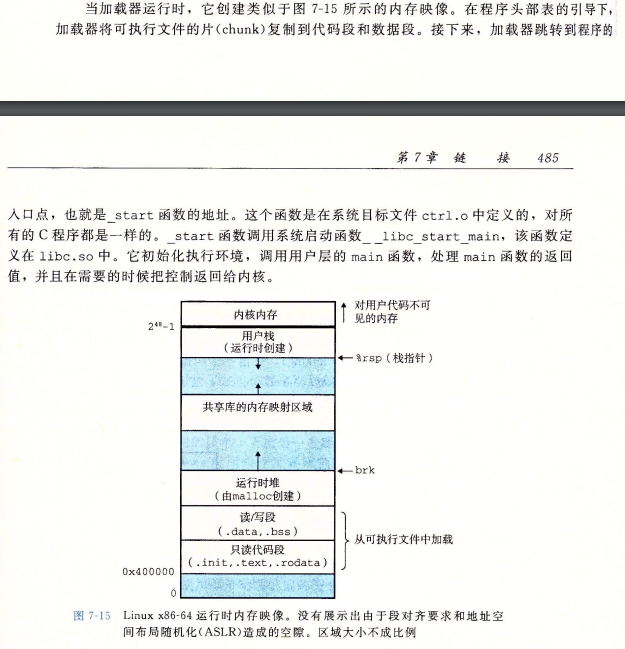
加载可执行目标文件
每个 Linux 程序都有一个运行时内存映像,类似于图 7-15 中所示。在 Linux x86-64 系统中,代码段总是从地址 0x400000 处开始,后面是数据段。运行时堆在数据段之后,通过调用 malloc 库往上增长。堆后面的区域是为共享模块保留的。用户栈总是从最大的合法用户地址( 2 48 − 1 2^48}-1 248−1)开始,向较小内存地址增长。栈上的区域,从地址 2 48 − 1 2-1 248−1 开始,是为内核( kernel)中的代码和数据保留的,所谓内核就是操作系统驻留在内存的部分。
为了简洁,我们把堆、数据和代码段画得彼此相邻,并且把栈顶放在了最大的合法用户地址处。实际上,由于.data 段有对齐要求,所以代码段和数据段之间是有间隙的。同时,在分配栈、共享库和堆段运行时地址的时候,链接器还会使用地址空间布局随机化。虽然每次程序运行时这些区域的地址都会改变,它们的相对位置是不变的。
当加载器运行时,它创建类似于图 7-15 所示的内存映像。在程序头部表的引导下,加载器将可执行文件的片( chunk)复制到代码段和数据段。接下来,加载器跳转到程序的入口点,也就是 _start 函数的地址。这个函数是在系统目标文件 ctrl.o 中定义的,对所有的 C 程序都是一样的。 _start 函数调用系统启动函数 __libc_start_main,该函数定义在 libc.so 中。它初始化执行环境,调用用户层的 main 函数,处理 main 函数的返回值,并且在需要的时候把控制返回给内核。





plt 和 got 表
Linux 链接器支持一个很强大的技术,称为库打桩 (library interpositioning), 它允许你截获对共享库函数的调用,取而代之执行自己的代码。